High-level map of SrotaX modules, runtimes, and extension points. Use this to
select the right entry point and understand how pieces compose.
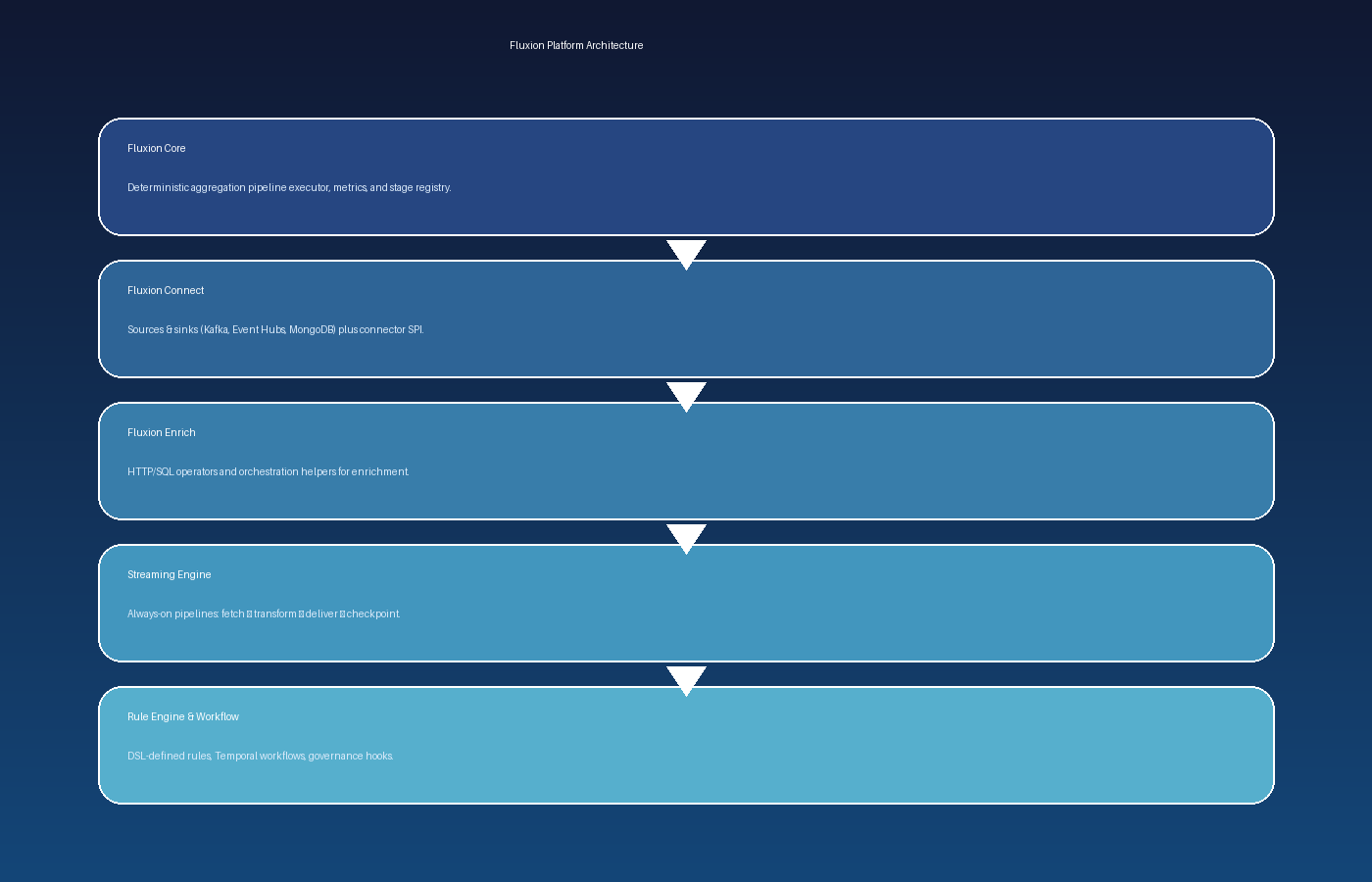
1. Layered architecture
Connect → Streaming Engine → Rule Engine
│ │
└──────►│ │
▼ │
SrotaX Core ◄──────┘
│
Enrichment operators (Connect)
| Layer |
Purpose |
| SrotaX Core |
Deterministic aggregation engine (stages/operators), expression evaluator, metrics, registries. |
| SrotaX Connect |
Source/sink connectors (Kafka, HTTP sink, custom SPI) plus enrichment operators. |
| Streaming Engine |
Always-on pipelines (fetch → transform → deliver → checkpoint). |
| Rule Engine |
JSON/DSL-defined rule sets for decisioning and governance workflows. |
2. Module checklist
3. Selecting an entry point
| Need |
Start here |
| Run aggregation pipelines in-process |
fluxion-core (see Usage Guide) |
| Ingest from Kafka/HTTP |
fluxion-connect + Streaming Engine |
| Enrich with HTTP/SQL lookups |
Enrichment operators in fluxion-connect |
| Declarative rule authoring/governance |
fluxion-rules (Rule Engine) |
| Long-running stream processing |
Streaming Engine (with Connect) |
4. Extending SrotaX
- Add capabilities at the lowest layer.
- New operator/stage → contribute to SrotaX Core.
- New connector → implement SPI in SrotaX Connect.
- New enrichment behaviour → extend the operators in SrotaX Connect.
- Expose through runtimes. Surface new operators/connectors to rule/streaming
engines so users can adopt them immediately.
- Document + test. Update docs/tests alongside the new contribution to keep
assistants and developers aligned.
5. Integration patterns
| Scenario |
Modules involved |
Notes |
| Request/response service with pipeline execution |
Core |
Cache parsed stages, use PipelineExecutor. |
| Manual approval workflow (Temporal) |
Core + Rules + Workflow integration |
See Temporal Bridge. |
| Real-time enrichment from Kafka to HTTP |
Core + Connect + Streaming |
Use streaming pipeline with Kafka source and HTTP sink/operators. |
| Analytics batch job with JDBC source |
Core + custom source |
Extend streaming SPI or use executor in batch mode. |
6. References & next steps
This overview keeps the module map clear; dive into the linked guides for deeper,
LLM-ready documentation.